


Lately, it can feel as if you’re being followed on the internet. The products we search for on e-commerce websites shadow us on social media platforms in the form of advertisements, while the news websites we frequent seem to always appear at the top of our searches.
These ‘benefits’ are what consumers have received in exchange for the volumes of personal data they have gifted big tech firms over the years. In other words, while we have received personalised suggestions that make it easier to find products we enjoy, companies like Facebook and Google have multiplied their income many times over.
Until last year, many of us gave little thought as to whom had access to our personal data and what they were doing with it. Several high-profile data breaches and allegations of data misuse later, however, and the issue has been cast well and truly into the international spotlight.
While consumers claim to be concerned about their online privacy, they do little to protect their personal data
The concept of data ownership – previously unheard of among the masses – is now gaining steam. In fact, even musician Will.i.am has penned an article on the subject, arguing in The Economist that data should be regarded as a human right – one that people are compensated for.
Privacy paradox
Experts (and rap stars) have argued that data should be treated like property – something people can rent out or sell for fair compensation. As one example goes, you should own your data like you own a vehicle: if someone took your car and rented it out for others’ benefit, you would care. In reality, however, when our personal data is gathered, stolen or sold, we appear far less worried than we would about any physical object.
The idea that consumers don’t own or control their personal data has long been embedded in internet culture; consumers have grown accustomed to the idea their data is not their own. This changed in 2018, however, when it was revealed that the personal data of more than 50 million Facebook users had been improperly acquired by political-consulting firm Cambridge Analytica ahead of the 2016 US presidential election. The New York Times later reported that Facebook also held data-sharing deals with firms such as Netflix and Spotify, giving said companies access to users’ private messages.
Although Facebook users expressed outrage at the lack of care demonstrated by the social media giant, many remained complacent about the protection of their data. Daryl Crocket, CEO of data consulting firm ValidDatum, told European CEO that consumers are careless due to a lack of understanding, which is fuelled by the complexity of the subject and the absence of clear, concrete solutions: “Most media coverage fails to help the public connect the dots to what a breach really means to them personally. After a while, people become desensitised to the messages and accept the condition of ‘data insecurity’.”
This plays into a phenomenon called the ‘privacy paradox’ – the idea that while consumers claim to be concerned about their online privacy, in reality they do little to protect their personal data. According to Vince Mitchell, a professor of marketing at the University of Sydney Business School, this suggests consumers lack the skills and knowledge – rather than the motivation – to better protect their data.
“With so many ways privacy can be protected… [across] each different app or website, it’s not possible for [a] consumer to know how to navigate even frequently used websites like Facebook, let alone the millions of apps available,” Mitchell said.

Data is intangible and hard to visualise; it is also widely dispersed and largely inaccessible. These qualities make it difficult for consumers to attribute any value to the personal information they release into cyberspace.
According to a survey of nearly 300 London-based business students included in Mitchell’s research, 96 percent of participants failed to understand the scope of the information they were giving away when registering to use apps or websites. Another study of MIT students, published by the National Bureau of Economic Research, found that 98 percent would give away their friends’ email addresses in exchange for free pizza.
In an article published by the Conversation, Mitchell, along with two co-authors, argued that the reality of what consumers were giving away when they agreed to share their data could be made clearer with added specificity: “Imagine if an app asked you for your contacts, including your grandmother’s phone number and your daughter’s photos. Would you be more likely to say no?” This thought experiment helps ground vague data requests in reality.
But while recent data breaches have lifted the lid on the exploitation of personal data, a solution to the problem has failed to materialise. “Raising awareness is only helpful if you can then do something about the thing you’ve been made aware of,” Mitchell told European CEO. “This is too complex for consumers to do themselves… [so] regulators need to take more responsibility on consumers’ behalf.”

The value of data
In the book Radical Markets: Uprooting Capitalism and Democracy for a Just Society, Eric Posner and E Glen Weyl argued that titans of the digital economy – or ‘siren servers’, as they referred to them – have exploited the lack of public understanding regarding artificial intelligence (AI) and machine learning to freely collect the data consumers scatter around the internet.
Personal data is a vital component of the success tech and social media giants have experienced in recent years – as such, it’s extremely valuable. This is because it allows companies to squeeze more money out of consumers through targeted advertisements and customisations that keep users engaged with their platform. AI algorithms, which can be programmed to identify and predict exactly what consumers want, are boosting the value of data even further.
According to Mitchell, the personal data industry generates around $200bn (€175.2bn) in revenue each year. But despite the fact companies are constantly buying, selling and trading data among themselves in a bid to increase profits, the consumers who generate it are not compensated. “This is the source of the record profits that make [siren servers] the most valuable companies in the world,” Posner and Weyl wrote.
The idea that consumers don’t own or control their personal data has long been embedded in internet culture
The pair went on to argue that data creation is a form of labour, one that has been systematically undervalued in the same way ‘women’s work’ has been unfairly compensated throughout history: “Most people do not realise the extent to which their labour – as data producers – powers the digital economy.”
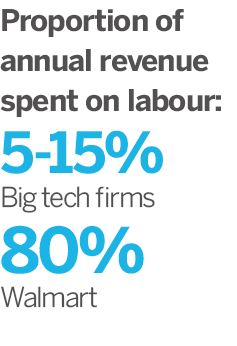
To demonstrate this point, Posner and Weyl compared the pay structures of some of the world’s largest technology companies with retailer Walmart. While the big tech firms spend between five and 15 percent of their annual revenue on labour, Walmart spends as much as 80 percent. This disparity is due to the fact the former receive so much free data from consumers and do not, therefore, require large workforces to generate income. “People’s role as data producers is not fairly used or properly compensated,” Posner and Weyl wrote. “This means that the digital economy is far
behind where it should be.”
However, there are some encouraging signs of change, and Europe is at the forefront. The EU’s General Data Protection Regulation (GDPR), which launched in May 2018, ensures businesses are more transparent about the personal data they hold on customers, as well as what they do with it. Additionally, the EU’s proposed ePrivacy Regulation, which would complement GDPR, aims to address the confidentiality of electronic communications and the tracking of internet users.
According to Crocket, the new rules will also benefit businesses: GDPR and the ePrivacy Regulation will improve visibility, providing companies with the necessary education and guidance on the fundamentals of data ownership and privacy. This is helpful, as businesses need motivation to change. “Without standards and regulations, businesses typically pursue only internally beneficial goals and rarely self-govern without profit [as a] motive or external pressure,” Crocket said.
But while these are steps in the right direction, some experts argue consumers will remain passive, happily ticking consent boxes to access their favourite websites. Instead, it has been suggested that the only way to get the public to pay attention is to give consumers ownership of their personal data and transform an idle form of entertainment into an economic asset.
The exact amount of compensation consumers would receive for their data is not yet known and would likely vary depending on its quality. In the first few years, estimates range between a couple of hundred euros per year and a few thousand. And as Posner and Weyl point out, the importance of data labour as a source of income will be determined by the significance and scope of AI in the future.
Creating a framework
How such a system of data ownership and compensation would work is a question that has not yet been definitively answered. According to Mitchell, the fact that companies are paying each other for personal data means frameworks for consumer compensation should already exist. New methods could also be developed through blockchain technology.
Theoretically, such structures would empower customers to determine which types of data they wanted to give up, protecting against blanket data collection in the process. In other words, while a consumer may be happy to sell their browsing history to a company wanting to target individuals in the same demographic, they may be less willing to provide access to their private messages in exchange for personalised music recommendations. With a transparent framework, consumers could choose what they sell and to whom.
As the big tech/Walmart pay comparison shows, however, treating data as labour could prove a major setback to some of the largest and most influential companies on the planet. What’s more, data ownership relies on transparency, and some experts believe there is little chance of businesses like Facebook or Google ever agreeing to an arrangement wherein they have to pay consumers to share user data with advertisers.
Eric Tjong Tjin Tai, a professor at Tilburg Law School and an expert in IT law, told technology-focused blog Engadget that it was already too late to take back dominion of our data: “Once you provide [companies] access, you’ve lost control.” Put simply, as consumers do not have a full log of everything companies already know about them, there can be no conversation about ownership.
The only option would be to fully outlaw the way Facebook collects data, which is something Tjong Tjin Tai doesn’t believe will ever happen: “In the end, the only thing [that] would work is regulation. For physical stuff, you can do without regulation, because you can just chase [someone] off your property and protect your things by putting [them] in [a] vault and so on. Data is intangible in that respect.”
Posner and Weyl agreed that pressure from regulators would be needed to catalyse change, as it is “plausible that the structure of the industry makes it unlikely that any private entity will voluntarily… shift to a more productive model”. Other issues with a framework of data ownership include the potential for individuals to take advantage of the arrangement. Microsoft, for example, once experimented with paying its users for data, but bots – offering no usable information – began to exploit the system.

Data brokers
Even with a solid framework, it will be challenging to get consumers – who typically do not even read the terms of service for online agreements – to comprehend the nuances and legal complexities of data ownership. This is where digital advisors could come in. “In any complex consumer purchase, the way around [misunderstandings] is usually to provide an intermediary who helps consumers navigate [the problem] and acts on their behalf,” Mitchell explained.
Companies such as CitizenMe, people.io and Datacoup allow consumers to store and control all of their personal data in one app. These start-ups remain small and largely unknown to consumers, but they present a significant step towards data ownership as a viable possibility.
“[By] connecting consumers to the potential buyers of their data, these types of applications are solving a large part of the problem,” Crocket said. “Consumers input their data (or allow their data to be collected) on dozens of sites per week, so being able to manage those ‘data for sale’ relationships in one application is a timesaver.”
With a transparent data ownership framework, consumers could choose what they sell and to whom
Posner and Weyl believe an intelligent digital advisor could also offer the added benefit of suggesting more lucrative data opportunities. Since the concept is still so new, only time will tell whether these apps will be successful in the long term. Mitchell warned that these companies, while an excellent addition to helping solve the privacy problem, must work within a regulatory framework such as GDPR to avoid becoming part of the problem.
Elsewhere, some companies are working to solve the issues presented by data ownership directly for their customers. José María Álvarez-Pallete López, CEO of Spanish telecoms giant Telefónica, one of the largest mobile network providers in the world, believes consumers should have control of their own data, including knowing how it is used and whether it can be moved with them if they change service providers.
Telefónica has already handed over some data control to its customers through a platform called Aura, which was launched in 2018. While Aura is a digital assistant, it provides customers with a ‘personal data space’ that keeps a log of all interactions with the company. Eventually, Aura will give customers an overview of all of the data they generate – such as location and payment history – and control over how the data is used.
Companies will certainly face a number of risks if the ownership of data is passed on to consumers. Any tech firm that relies on free access to data as a cornerstone of its business model, for example, will inevitably take a financial hit if it is forced to pay consumers for the privilege. What’s more, Posner and Weyl believe if consumers become aware of how much data businesses have already collected, the “creepiness” factor could deter them from engaging in online interactions altogether.
It is difficult to predict just how much the online business landscape would be impacted if consumers took back control of their data. It is becoming increasingly clear, though, that the true value of personal data should lie with the consumers who created it.